Supervised Speech Separation Based On Deep Learning An Overview 基于深度学习的说话人分离算法综述
DeLiang Wang, Jitong Chen (Submitted on 24 Aug 2017 (v1), last revised 15 Jun 2018 (this version, v2))
I.INTRODUCTION
II.CLASSIFIERS AND LEARNING MACHINES
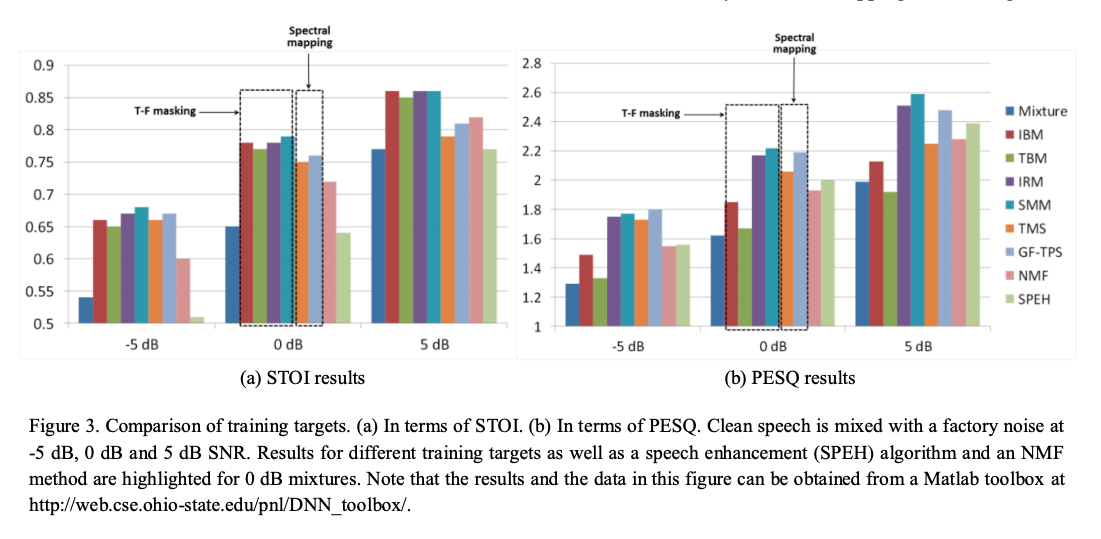
III.TRAINING TARGETS
主要有两类训练目标
- masking-based targets
- mapping-based targets
语音分离衡量标准
- 信号层级的 目标是量化语音增强或者干扰消除的程度,除了传统饿SNR,还有语音失真和噪声残留,还包括 SDR (source-to-distortion ratio), SIR (source-tointerference ratio), and SAR (source-to-artifact ratio)
- 听觉层级的
A. Ideal Binary Mask
基于一段带噪信号的二维$T-F$表达,比如听觉谱 Cochleagram或者语谱图 Spectrogram,做如下二分类
\[IBM=\begin{cases} 1, & \text{if $SNR(t,f)>LC$} \\ 0, & \text{otherwise} \end{cases}\]其中$LC$是一个阈值,产生label的时候需要对频谱上的每一个$(T,F)$点做标注,check是否是0还是1,这是一个有监督的分类任务,loss函数一般用交叉熵。
B. Target Binary Mask
类似IBM也是做二分类,和IBM不同的是,label来源不是SNR,而是每个$(T,F)$点的语音信号能量是否超过固定干扰。
C. Ideal Ratio Mask
IBM和TBM属于hard label,IRM属于soft label
\[IRM=(\frac{S(t,f)^2}{S(t,f)^2+N(t,f)^2})^{\beta}\]$S(t,f)^2$和$N(t,f)^2$表示每个$(T,F)$点的语音信号能量和噪声能量,$\beta$是可调参数。
- 当$\beta=0.5$时,相当于做开方,能很好的维持语音信号,这里假设$S(t,f)^2$和$N(t,f)^2$是不相关的,这个假设在非加性噪声场景就不适用,比如混响场景。
- 当$\beta=1$,就类似经典的维纳滤波器
IRM的loss函数通常会用MSE。
D. Spectral Magnitude Mask
SMM或者FFT-MASK是基于干净语音和带噪语音的短时傅里叶变换STFT,
\[SMM(t,f)=\frac{\vert S(t,f) \vert}{\vert Y(t,f) \vert}\]$\vert S(t,f) \vert$和$\vert Y(t,f) \vert$表示干净语音和带噪语音的频谱幅值。和IRM不同的是,SMM取值没有限制在1以内。为了获得分离后的语音,我们在频域幅值上应用SMM或者它的估计,然后再合成出分离后的语音。
E. Phase-Sensitive Mask
PSM在SMM的基础上做了扩展
\[PSM(t,f)=\frac{\vert S(t,f) \vert}{\vert Y(t,f) \vert} \cos \theta\]$\theta$表示干净语音相位和带噪语音相位的相位差。引入相位差带来更高的SNR,比SMM估计出的干净语音更好。
F. Complex Ideal Ratio Mask
cIRM是IRM的复数域版本,与IRM相比能更好地从带噪语音里重建干净语音
\[S=cIRM * Y\]这里$S$和$Y$是干净语音和带噪语音的STFT,$$表示复数乘法。cIRM*计算如下
\[cIRM=\frac{Y_rS_r+Y_iS_i}{Y_r^2+Y_i^2}+i\frac{Y_rS_i-Y_iS_r}{Y_r^2+Y_i^2}\]其中$Y_r$和$Y_i$是带噪语音的实部和虚部,$S_r$和$S_i$是干净语音的实部和虚部,因此参数$cIRM$也是一个复数。
G. Target Magnitude Spectrum
从带噪语音里直接估计干净语音的频谱,这里频谱可能是幅值谱,也可能是mel谱,通常会去log来压缩动态范围。TMS的形式是取对数而且归一化的频谱。 loss函数是MSE。
H. Gammatone Frequency Target Power Spectrum
与TMS不同的是,频谱是基于伽马滤波器的听觉谱。
I. Signal Approximation
SA的想法是,训练一个ratio mask来最小化干净语音和估计语音的频谱幅值差值。
\[SA(t,f)=[RM(t,f)\vert Y(t,f) \vert - \vert S(t,f) \vert]^2\]$RM(t,f)$是SMM中的ratio mask,因此SA可以被看做是,ratio mask和spectral mapping的组合,目标是寻求最大的SNR。 训练方式two-stage
- 用SMM做target训练
- fine-turn来减少波形之间的幅值差值 $SA(t,f)$
IV.FEATURES
- mel-domain features
- mel-frequency cepstral coefficient (MFCC)
- delta-spectral cepstral coefficient (DSCC)
- linear prediction features
- perceptual linear prediction (PLP)
- relative spectral transform PLP (RASTA- PLP)
- gammatone-domain features
- gammatone feature (GF)
- gammatone frequency cepstral coefficient (GFCC)
- zero-crossing features
- zero-crossings with peak-amplitudes (ZCPA)
- autocorrelation features
- relative autocorrelation sequence MFCC (RAS-MFCC)
- autocorrelation sequence MFCC (AC-MFCC)
- phase autocorrelation MFCC (PAC-MFCC)
- medium-time filtering features
- power normalized cepstral coefficients (PNCC)
- suppression of slowly-varying components and the falling edge of the power envelope (SSF)
- modulation domain features
- Gabor filterbank (GFB)
- amplitude modulation spectrogram (AMS)
- Pitch-based (PITCH) features
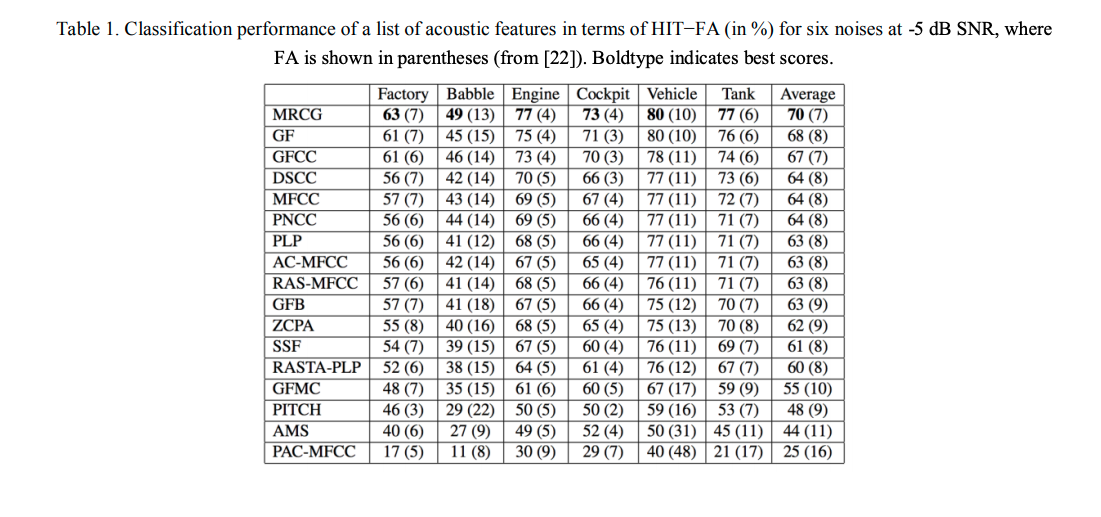
用group Lasso方法选择特征,推荐特征集合包括AMS, RASTA- PLP和MFCC。 这篇paper提出Multi-Resolution Cochleagram (MRCG) ,基于频谱不同精度计算四个cochleagrams,保证提供足够的本地和全局contex。然后提出的特征用auto-regressive moving average (ARMA)滤波器做后处理,用HIT−FA rate作为衡量指标
HIT−FA rate HIT指的是语音点被正确分类,FA指的是噪音点被错误分类
特征选择对于性能影响很大。
V.MONAURAL SEPARATION ALGORITHMS
单通道语音增强,去混响,去噪,说话人分离。
A. Speech Enhancement
paper1提出基于子带做DNN映射,比全频带做映射性能更优。 paper2提出不连续的DNN层之间加skip connection可以提高性能。 paper3提出同时将mask和mapping作为训练目标。 最近有很多paper提出端到端的分离方法,中间不需要转换成T-F表达。这种方法的优点是,在重构增强语音时不必要用到带噪语音的相位信息,带噪语音的相位信息对语音质量危害很大。paper4提出全卷积网络,全连接很难映射波形中的高频低频成分,而卷积更容易做到。 paper5提出speech enhancement GAN (SEGAN),generator是一个全卷积网络用于增强降噪,discriminator和generator结构一样。SEGAN的结果比传统mask或者mapping方法要差。paper6也是用GAN方法,G试图从带噪信号里增强频谱,D试图来区分增强频谱和干净频谱,这种方法的GAN性能可以接近DNN方法。
B. Generalization of Speech Enhancement Algorithms
考虑三个方面的泛化能力
- 噪声
噪音有平稳和非平稳,训练中选择的噪音总是有限的 paper7提出的方法是noise perturbation,或者说frequency perturbation,频谱上的每个点在纵轴频域方向随机跳变,方法如下 对于每一个T-F点赋一个随机值,服从均匀分布 \(r(f,t)\sim U(-1,1)\)
根据当前点附近的点的随机值,计算出perturbation factor $\delta(f,t)$
\[\delta(f,t) = \frac{\lambda}{(2p+1)(2q+1)} \sum_{f'=f-p}^{f+p} \sum_{t'=t-q}^{t+q} r(f',q')\]这里$p$和$q$控制平滑区域大小,$lambda$控制perturbation之后的幅值。这些都是超参数。最终perturbation之后的频谱可以写成
\[S'(f,t)=S(f+\delta(f,t), t)\]paper[^195,196]提出的方法是噪音感知的训练,输入特征向量包含一个显示的噪音估计,通过binary mask估计出噪音。 paper8系统地讨论了噪音泛化能力,DNN用于在连续几帧内预测IRM,输入特征是GF特征,训练语料中包含噪声125小时,混合正样本380小时,结论是要用大量不同类型的噪音。
- 说话人
用特定说话人训练的分离系统可能不适配不同说话人。一种方法是增大说话人训练集。另一种方法是模型结构,发现随着训练集中的说话人数目增加,DNN模型性能下降,但是LSTM模型性能上升。在测试集上LSTM也一直优于DNN。
- SNR
可以在训练中多增加几组SNR值以提高SNR泛化能力。事实上泛化能力对SNR并不敏感,虽然训练过程中只有有限几组SNR组合,但是帧级别和频谱点级别的SNR变化很大,提供了足够的多样性来支撑泛化能力。还有一种方法是在训练中逐步增大隐层节点数,来适应更低的SNR条件。
C. Speech Dereverberation and Denoising
房间混响是原始信号的卷积和房间冲击响应room impulse responses (RIRs),它在时域和频域都会让信号失真。 paper9首次将DNN用于去混响,DNN模型用于映射一段混响语音和无混响语音,频域基于cochleagram,更新的paper10,频域基于spectrogram,同时进行去混响和降噪。
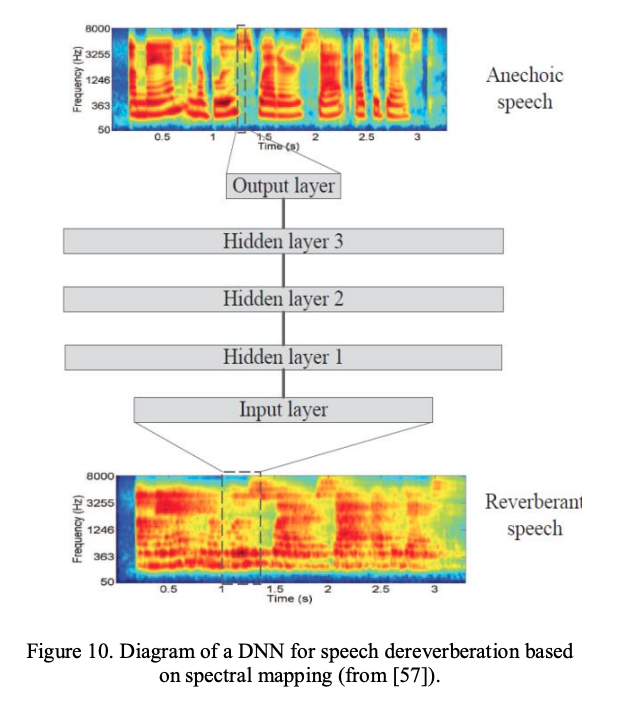
paper11观察到,当特征提取的帧长和帧移根据混响时间$T_60$随机选择时,去混响性能变好。$T_60$定义了声音减弱60db所需要的时间。训练中将$T_60$包含在特征中,应用时先估计$T_60$,然后用$T_60$来随机选择特征提取的帧长和帧移 paper12中同时预测static,delta,acceleration特征。static特征指干净语音的幅值log,后两者从static特征中得到。 paper13中提出,去混响更适合频域mapping,而降噪更适合T-F域masking,因此构建了一个two-stage DNN,第一步做masking降噪,第二步mapping去混响。 paper14考虑到混响带噪语音的相位对重建过程带来的负面影响,扩展了时域信号重建技术。
D. Speaker Separation
说话人分离是从一段多说话人混合的语音中提取出每个说话人的语音。
- speaker dependent speaker separation 说话人相关 训练和测试都是同一批说话人,
- target dependent speaker separation 目标说话人相关 分离的目标说话人固定
- speaker independent speaker separation 没有约束
paper15最早提出将DNN用于说话人分离,属于speaker dependent和target dependent,本质上还是通过找binary或者ratio mask来还原原始信号。在第$t$帧的两个说话人ground true语音频谱是$S_1(t)$和$S_2(t)$,估计得语音频谱是$\tilde{S_1(t)}$和$\tilde{S_2}(t)$,那么训练中loss是
\[\frac{1}{2} (\sum_{t}(\vert \vert S_1(t)-\tilde{S_1}(t) \vert \vert^2 \\ + \vert \vert S_2(t)-\tilde{S_2}(t) \vert \vert^2) \\ - \gamma \vert \vert S_1(t)-\tilde{S_2}(t) \vert \vert^2 \\ - \gamma \vert \vert S_2(t)-\tilde{S_1}(t) \vert \vert^2)\]其中$\gamma$是可调参数。
speaker independent可以看做是无监督聚簇,每个说话人的T-F单元聚成一簇。这个聚簇的过程应该是根据说话人数目的不同动态变化的。 paper16最早用DNN解决speaker independent的说话人分离,他们的方法称为deep clustering,包含基于DNN的特征学习和频谱聚簇。 基于聚簇的方法天生适合speaker independent任务,而基于mask/mapping的方法,在实现的时候就将输出和特定用户绑定,适合speaker dependent任务。 如何将输出和特定用户解耦合,使得基于mask/mapping的方法也能适用于speaker independent任务?paper17给出了解决方法,如下图
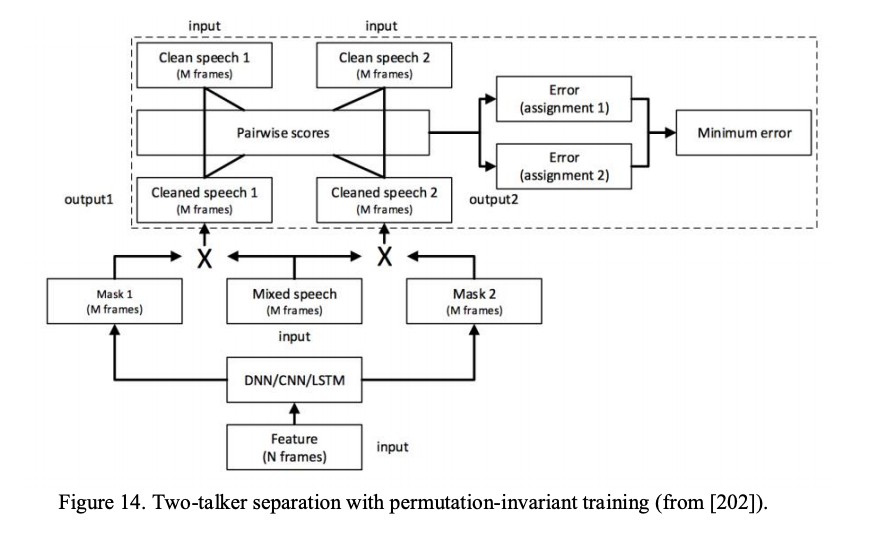
训练一个DNN来输出2个mask,每个都用来从带噪语音中生成干净语音的估计,DNN训练中loss函数是动态的。 假设目标是分出$S$个语音信号,那么对应就训练$S$个mask,每个mask估计出来一个cleaned语音,和$S$个参考clean语音两两组合,一共有$S!$种组合,分别计算$S!$种组合的MSE。选择其中MSE最小的一种组合,然后模型就训练减少这一种组合的特定MSE。也就是说同时推断出正确的mask-reference组合,和减少误差。这种方式训练每次输出的mask/output和speaker的对应关系可能会变。带来的问题是,前向计算一段连续语音时,同一个用户的语音可能会在不同的output或者mask跳跃,所以需要额外的根据用户重排。解决重拍问题,不是基于每个语音片段计算MSE,而是基于整句话计算MSE.
REFERENCES
-
J. Du and Y. Xu, “Hierarchical deep neural network for multivariate regresss,” Pattern Recognition, vol. 63, pp. 149- 157, 2017. ↩
-
M. Tu and X. Zhang, “Speech enhancement based on deep neural networks with skip connections,” in Proceedings of ICASSP, pp. 5565-5569, 2017. ↩
-
H. Zhang, X. Zhang, and G. Gao, “Multi-target ensemble learning for monaural speech separation,” in Proceedings of Interspeech, pp. 1958 -1962, 2017. ↩
-
S.-W. Fu, Y. Tsao, X. Lu, and H. Kawai, “Raw waveformbased speech enhancement by fully convolutional networks,” arXiv:1703.02205v3, 2017. ↩
-
S. Pascual, A. Bonafonte, and J. Serra, “SEGAN: Speech enhancement generative adversarial network,” in Proceedings of Interspeech. pp. 3642-3646, 2017. ↩
-
D. Michelsanti and Z.-H. Tan, “Conditional generative adversarial networks for speech enhancement and noiserobust speaker verification,” in Proceedings of Interspeech. pp. 2008-2012, 2017. ↩
-
J. Chen, Y. Wang, and D.L. Wang, “Noise perturbation for supervised speech separation,” Speech Comm., vol. 78, pp. 1-10, 2016. ↩
-
J. Chen, Y. Wang, S.E. Yoho, D.L. Wang, and E.W. Healy, “Large-scale training to increase speech intelligibility for hearing-imparied listeners in novel noises,” J. Acoust. Soc. Am., vol. 139, pp. 2604-2612, 2016. ↩
-
K. Han, Y. Wang, and D.L. Wang, “Learning spectral mapping for speech dereverebaration,” in Proceedings of ICASSP, pp. 4661-4665, 2014. ↩
-
K. Han, et al., “Learning spectral mapping for speech dereverberation and denoising,” IEEE/ACM Trans. Audio Speech Lang. Proc., vol. 23, pp. 982-992, 2015. ↩
-
B. Wu, K. Li, M. Yang, and C.-H. Lee, “A reverberationtime-aware approach to speech dereverberation based on deep neural networks,” IEEE/ACM Trans. Audio Speech Lang. Proc., vol. 25, pp. 102-111, 2017. ↩
-
X. Xiao, et al., “Speech dereverberation for enhancement and recognition using dynamic features constrained deep neural networks and feature adaptation,” EURASIP J. Adv. Sig. Proc., vol. 2016, pp. 1-18, 2016. ↩
-
Y. Zhao, Z.-Q. Wang, and D.L. Wang, “A two-stage algorithm for noisy and reverberant speech enhancement,” in Proceedings of ICASSP, pp. 5580-5584, 2017. ↩
-
Y. Wang and D.L. Wang, “A deep neural network for timedomain signal reconstruction,” in Proceedings of ICASSP, pp.4390-4394, 2015 ↩
-
P.-S. Huang, M. Kim, M. Hasegawa-Johnson, and P. Smaragdis, “Deep learning for monaural speech separation,” in Proceedings of ICASSP, pp. 1581-1585, 2014. ↩
-
J. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in Proceedings of ICASSP, pp. 31-35, 2016. ↩
-
D. Yu, M. Kolbak, Z.-H. Tan, and J. Jensen, “Permutation invariant training of deep models for speaker-independent 27 multi-talker speech separation,” in Proceedings of ICASSP, pp. 241-245, 2017. ↩